SPOT
An AI trust intelligence platform that surfaces risk signals in crypto messages, founder pitches, and on-chain wallets — before capital moves.
"Spot the signal. Before the scam."
The problem
Crypto has a trust problem that web2 fraud detection was never built for. A founder DM, a "private alpha" group chat, a wallet that came out of nowhere with conveniently aged history — any of these can move millions of dollars in minutes. There's no Stripe sitting between you and the bad actor. By the time the screenshots hit X, the money's already gone.
The signal is in two places: the language of the pitch (manipulation patterns, social-engineering tells, emotional incongruence) and the on-chain history of the counterparty (wallet provenance, transaction patterns, account age, verification status). Both are visible. Almost nobody was wiring them together at scale and surfacing the result fast enough to matter — before a decision, not after one.
What we did
- Designed the trust engine end-to-end: a two-engine architecture combining a deterministic signal scanner with a frontier language model running under structured output
- Built the curated scanner library of high-risk phrases, urgency markers, impersonation tactics, and structural signals associated with known scam patterns — same input always produces the same scanner output
- Designed and constrained the LLM prompt and schema for cautious-language, evidence-cited output with no ability to claim fraud or determine intent
- Built the calibrated weighting layer that merges the two engine outputs into a single read
- Built the on-chain enrichment pipeline: live XRPL account age, transaction history, balance, verification status, asset holdings — injected as system-trusted context under a hard latency cap
- Built the evaluation harness against a growing benchmark set spanning known scam patterns, legitimate communication, and adversarial prompt-injection attempts
- Designed the analyst-style "intel feed" UI — terminal aesthetic because the audience is technical and the format matches how an analyst actually thinks
- Set the boundary in product copy: SPOT surfaces signals. It does not prove intent, confirm fraud, or replace professional due diligence. That line is the entire reason the platform is trustworthy.
The result
Live in production at spot.army. Real scans run against real crypto messages and live on-chain artifacts. The intel feed is genuine working output — every line ("Analyzing emotional incongruence," "Cross-referencing XRPL history," "Elevated manipulation risk detected") is a real model pass producing a real signal.
What it actually does for users: shortens the gap between "this DM feels off" and "here's why it feels off, with receipts." Doesn't make the decision for you. Makes the decision a few seconds shorter and a few orders of magnitude more informed.
How SPOT works
SPOT analyzes messages, project announcements, and founder communication for patterns associated with scam tactics, social engineering, and deception risk. It combines a deterministic signal scanner with a frontier language model running in structured-output mode. Where a wallet address is present, SPOT cross-references live on-chain data and factors it into the read. The output is a scored read across five dimensions, with specific evidence surfaced from the submitted text.
Detection — two engines, one read
Every analysis runs two engines in parallel.
The signal scanner is deterministic. It pattern-matches against a curated library of high-risk phrases, urgency markers, impersonation tactics, and structural signals associated with known scam patterns. The same input always produces the same scanner output. This is the reproducible spine of every read.
Alongside the scanner, a language model evaluates the content holistically — context, tone, behavioral inconsistencies, and emotional manipulation patterns that pattern-matching alone can't capture. The model operates under a fixed structured-output schema with cautious-language constraints, and has no ability to claim fraud or determine intent. The two outputs are then merged through a calibrated weighting layer.
Dimensions — what SPOT measures
Every analysis surfaces five orthogonal dimensions, scored independently and weighted into a single overall read. Each dimension cites specific evidence from the submitted text.
Scam Pattern
Structural matches against known scam tactics — phishing, fake support, unverified partnerships, financial pressure patterns.
Social Engineering
Manipulation tactics — FOMO, urgency, authority impersonation, scarcity, trust shortcuts, identity pressure.
Behavioral Anomaly
Unusual communication patterns — sudden tone shifts, defensiveness, inconsistent claims, evasion.
Deception Risk
Signals of unverifiable claims, contradiction, overexplaining, confidence without evidence.
Emotional Incongruence
Mismatch between emotional framing and factual content — reassurance paired with urgent demands, certainty in uncertain situations.
Output — how the read is presented
The overall read is scored on a 0-to-100 scale and mapped to a five-tier risk classification.
Each result is paired with a separate read confidence signal, which reflects how strongly the two engines agreed and how much corroborating evidence was available. High confidence with a high risk score is the strongest possible read. Low confidence with any score is a recommendation to gather more context before acting.
On-chain enrichment — live data, not just language
When a wallet address appears in the submitted content or context fields, SPOT cross-references it against a live on-chain data feed: account age, transaction history, balance, verification status, and asset holdings. This data is injected into the analysis as system-trusted context.
A three-day-old wallet asking for funds reads very differently from a four-year-old, KYC-verified address — and that distinction shapes both the dimensional scores and the read confidence. On-chain enrichment runs in parallel with the language analysis under a hard latency cap. If it fails or times out, the analysis completes normally without it.
Calibration — how SPOT is benchmarked
SPOT is calibrated against a benchmark set of labeled examples spanning known scam patterns, legitimate project communication, and adversarial prompt-injection attempts. The benchmark set grows continuously as new patterns emerge in the wild.
We optimize aggressively against false positives. A wrong high-risk score erodes trust faster than a missed signal — so every change to the scanner library, the model prompt, or the weighting layer must clear the benchmark before it ships.
Data ethics — where intel comes from
SPOT operates on a strict public-or-voluntary data principle. We do not scrape private surfaces, intercept communication, or operate covert collection infrastructure. A trust intelligence platform that compromises trust to function is no platform we'd want to ship.
- Public on-chain data. The XRP Ledger is a public blockchain. SPOT reads account history, balances, trust lines, and verification status using public APIs — the same data anyone can pull from a block explorer.
- User-submitted content. You paste suspicious messages, threads, founder pitches, or emails you want analyzed. SPOT only reads what you choose to share. We do not retain content beyond your active session unless you explicitly save it.
- Voluntary partner integrations. Trusted partners — anti-rug bots, sniper bots, community-moderation services — write into SPOT through an authenticated API. Every submission is attributed to the partner that sent it. Partners onboard explicitly; nothing is silent.
- No private-surface scraping. No DMs, no closed channels, no auth-walled platforms accessed without permission. If you can't see it from the outside without an account, neither do we.
- No data resale. Intel submitted to SPOT — by users or partners — is used to score, classify, and (with consent) improve detection. It is never resold, sub-licensed, or repackaged into a data feed for third parties.
Limitations — what SPOT does not claim
- Not a lie detector. SPOT detects patterns, not intent. A message that scores High contains patterns associated with known scam tactics — it does not mean the sender is lying.
- Not a fraud verdict. Scores are indicators. A High score means a pattern cluster warrants scrutiny and independent verification — not that fraud has occurred.
- Not financial or legal advice. Do not use SPOT output as the sole basis for financial or legal decisions. It is a structured starting point for your own due diligence process.
- Not a blocklist. SPOT does not maintain a list of known scammers or blacklisted wallets. Every analysis is based on the content submitted, not prior history.
Full methodology — exact weighting, threshold calibration, scanner library composition, and benchmark results — is shared with integration partners and qualified investors under NDA.
Tech & systems
Selected screens
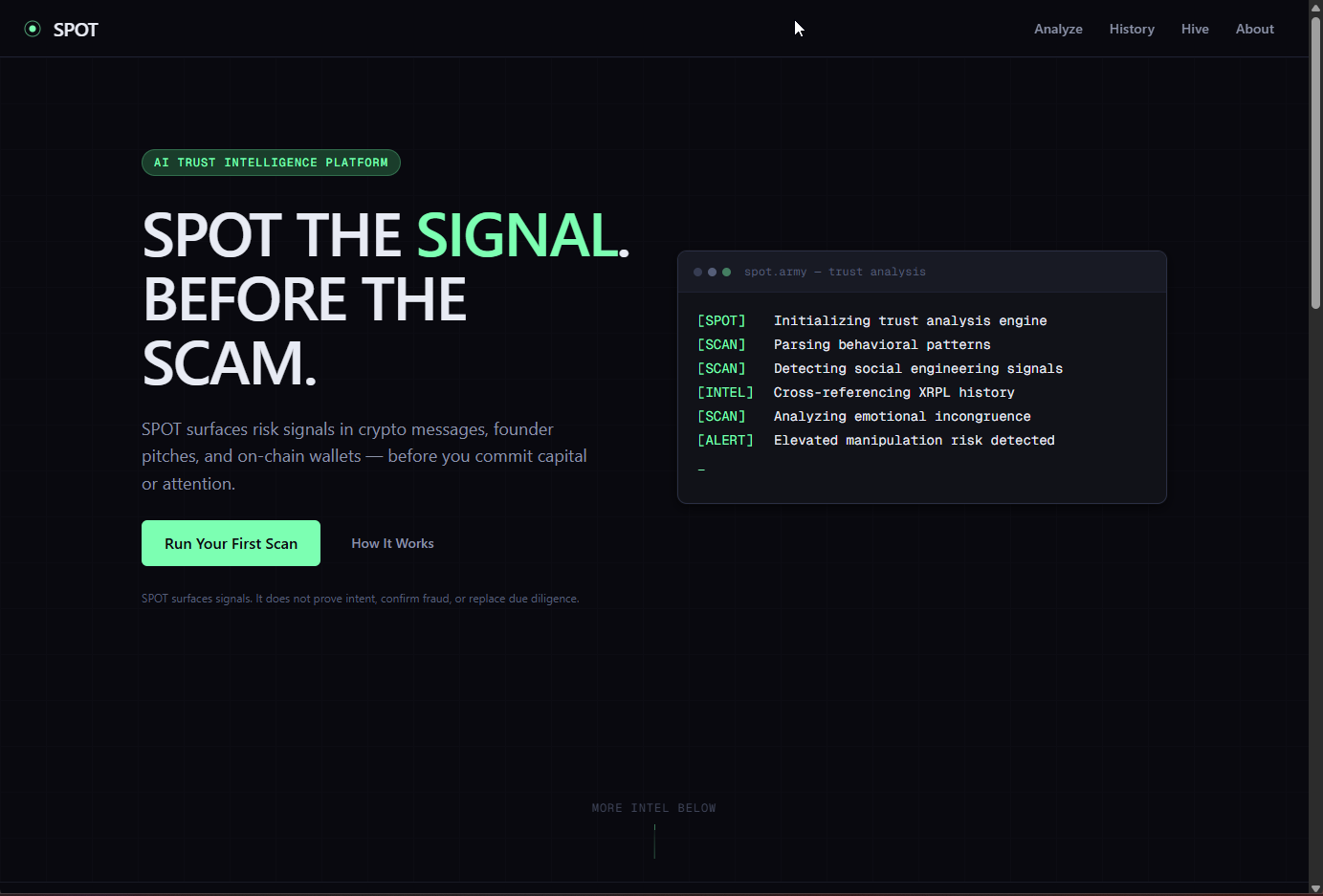
SPOT — homepage with live intel feed
Reflections
The hardest part wasn't the model selection or the on-chain pipeline. It was deciding what not to claim. Every shipped AI product faces the same temptation: overstate the verdict to win a demo. "This catches scammers." "This detects fraud." Easy to write. Impossible to actually do honestly with the current state of the art.
The discipline that makes SPOT credible is the opposite move. The product surfaces signals — it doesn't pronounce verdicts. "Elevated manipulation risk detected" is a true statement. "Scam" is not a statement an LLM can honestly make. Drawing that line in the product copy, in the UI, in the evals, and in the boundaries of what scans produce — that's the moat. Anyone can ship an AI scam-detector demo. Shipping one that doesn't lie to its users is harder, and it's why the product can grow.
The two-engine architecture is the second discipline. A pure LLM read is non-reproducible and adversarially fragile. A pure scanner is brittle and misses everything a pattern library hasn't yet seen. Running both in parallel and merging through a calibrated layer is more work to build, more work to evaluate, and the only way to ship something that holds up under serious use.
If you take one lesson from this for your own AI product: the eval harness is the product. Without it you can't honestly say what your system does. With it, you can hold the line on what to claim, and the trust compounds.
Shipping an AI product where honesty is the moat?
LLM systems with structured output. Eval harnesses. On-chain signal pipelines. Two-engine architectures. Technical UX for technical buyers. Tell us what you're building.
Tell us about it →